
【發佈會全片】OpenAI 最強GPT-5懶人包 免費用戶可用 CEO:「用完再用上一版本會好痛苦」

OpenAI於2025年8月8日正式推出新一代旗艦模型——GPT-5,即日起所有ChatGPT用戶(免費、Plus、Pro、Team、Enterprise)都用得,Plus用戶有更高用量,Pro用戶更可用「GPT-5 Pro」,未付費就自動切去GPT-5 mini版。
全球活躍用戶估計每週達7億人次
OpenAI自2022年底推出ChatGPT,全球活躍用戶估計每週達7億人次,2023年3月發佈GPT-4,隨後推出o系列及GPT-4.1、4.5。2025年8月8日,正式發佈GPT-5。OpenAI執行長奧特曼(Sam Altman)表示,用了GPT-5後,再試著回去使用GPT-4會很痛苦。
GPT-5五大革命性升級
- 更快更準:回應速度明顯提升,內容準確度顯著提高,「幻覺」(AI亂編)現象明顯減少。
- 安全機制新突破:遇到敏感/不當提問不會直接「拒絕回覆」,而會主動引導安全內容,整體互動感大升。
- 主動理解上下文、追問:對話中會主動釐清問題、提供追問,真正做到AI「思考夥伴」。
- 超自然語音模式:語音交互更自然貼近真人,細緻度遠勝上一代。
- 連接Google帳戶:可直接連Gmail和Google日曆,打通日常任務,效率up。
- 模型自適應:GPT-5自動判斷用哪個模型處理任務,不需用戶煩選。
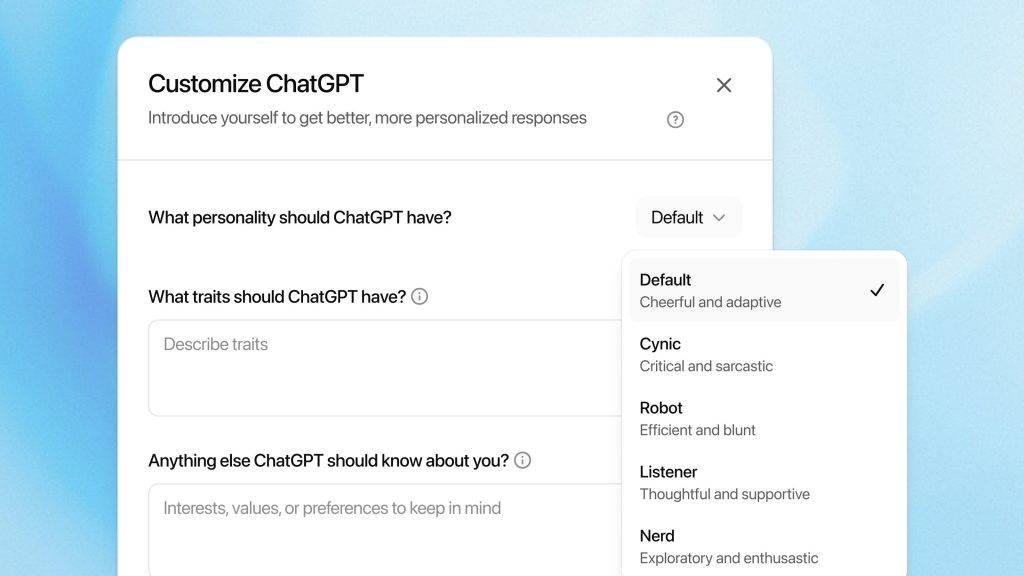
- 自訂ChatGPT外觀:訂閱用戶可個性化介面,日常操作更順手。
Demo現場一鳴驚人
OpenAI人員現場Show手,提示GPT-5設計法語學習網站(美觀、高度互動、追蹤進度、主題吸睛、設計小測驗),GPT-5直接自動生成網頁App,用戶可根據個人需求再作調整,經典工程師、教育工作者即用即改。
真正的知識型「AI博士」
OpenAI創辦人Sam Altman親證:「GPT-5在業界專業感前所未見,感覺像同博士級專家對話。」如罹癌者實例,女患者用GPT-5協助理解多份診斷報告、分析醫學術語,還能同步與醫生專業評估,AI變成「思考拍檔」而不只是工具。Altman形容:「GPT-5是首款任何領域都能像專家咁傾偈的AI。」
【詳細資料 發佈與可用性】
OpenAI 於2025年8月8日正式發佈新一代大型語言模型 GPT-5,定位為「統一系統」由多個子模型協同運作。
- 現在可用:所有付費版本、API、Codex CLI。
- 8月14日:Enterprise 和教育版。
- 逐步推出:免費用戶完整功能。
收費方案
- 免費版:適合偶爾使用、預算有限者。
- Plus ($20/月):日常專業使用。
- Pro ($200/月):提供最高準確度與無限使用。
- Team/Enterprise:組織級使用,需洽詢定價。
- API 收費 (每百萬 tokens):
- gpt-5:$1.25 輸入 / $10 輸出。
- gpt-5-mini:$0.25 輸入 / $2 輸出。
- gpt-5-nano:$0.05 輸入 / $0.40 輸出。
- gpt-5-chat-latest:$1.25 輸入 / $10 輸出。
核心數據
- 錯誤率:20% → 5%(降低75%)。
- 效率:輸出減少22%,工具調用減少45%(智慧提升)。
- 上下文:40K tokens(約30萬字)。
- 準確率:SWE-bench 74.9%,AIME 94.6%。
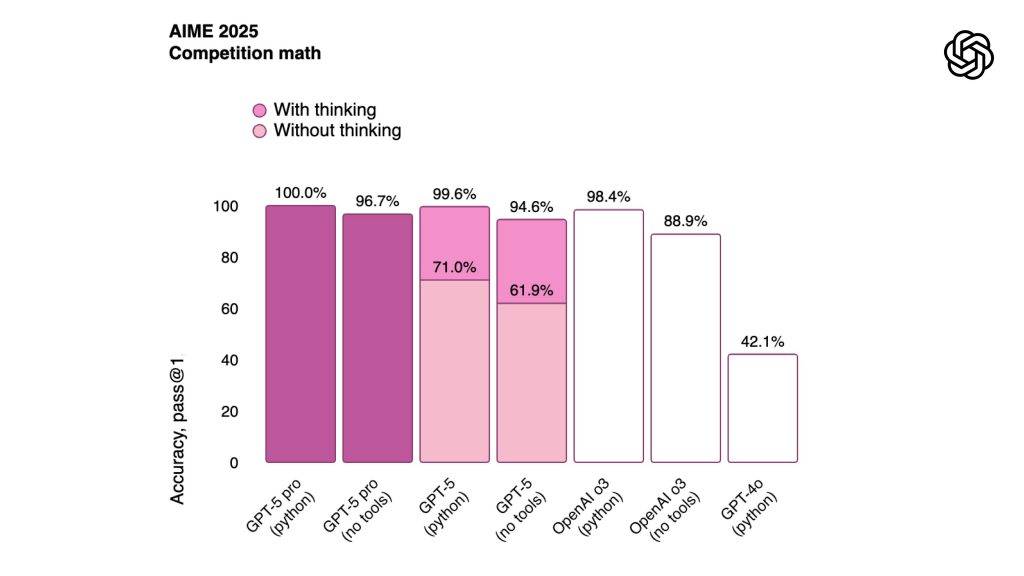
技術架構:快模型+思考模型
GPT-5由快速主力模型(gpt-5-main,GPT-4o後繼)與深度推理模型(gpt-5-thinking,o3後繼)組成,搭配即時路由器根據問題類型、複雜度及提示(如「需深入思考」)自動分流。當使用量達上限,系統切換至mini版本(如thinking-mini、thinking-nano)確保服務不中斷。使用者無需手動選擇,日常享快速回應,複雜問題獲深度分析。
突破一:更少「幻覺」與精確執行
- GPT-4o錯誤率20.6%,GPT-5思考模式降至4.8%(減75%)。
- 對「不存在圖像」問題,舊模型編造描述佔86.7%,GPT-5僅9%,顯著提升準確性與誠實度。
突破二:三大應用場景進展
- 程式編碼:SWE-bench成功率74.9%(前代30.8%),可完成價值112,000美元(約873,600港元)任務,如生成完整小球遊戲,展現獨立解決複雜問題能力。
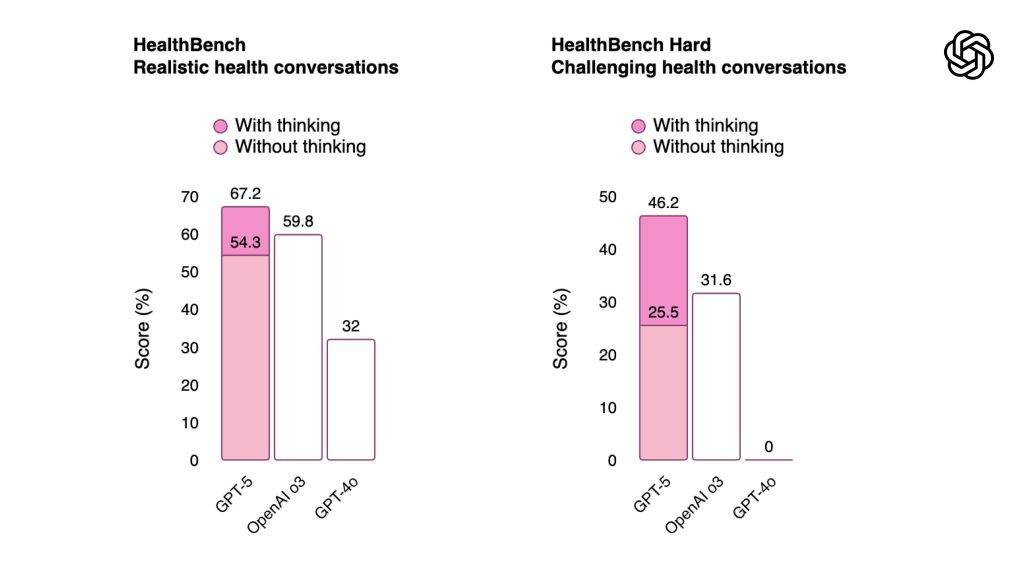
- 醫療健康資訊:HealthBench得分67.2%(前代32.0%),幻覺率3.6%(前代15.8%),可靠性提升超四倍。
- 專業寫作:如「京都寡婦」詩作,展現豐富意象與情感深度,從文字生成進化至文學創作。
突破三:更自然的互動體驗
- 諂媚回應率從14.5%降至6%,減少「擦鞋」行為。
- 新增四種性格模式:憤世嫉俗者、機械人、傾聽者、書呆子。
- 升級語音模式,引入「學習模式」,支援Gmail/Google Calendar情境化回覆(企業帳號受限)。
突破四:安全策略轉「安全完成」
- 從「直接拒答」轉為提供安全建議或替代方案,避免中斷體驗。
- 生物與化學領域設高風險防護,降低誤用風險。
- 影響:提升自然度、資訊可用性及安全精準度,適合專業應用。
突破五:思考過程透明化
- 例:Wi-Fi封鎖請求,GPT-5分析環境限制,坦言無法操作並提供Linux解決方案,展現誠實與專業。
突破六:數據全面超越GPT-4o
- 在數學推理(MATH)、程式除錯(HumanEval)、知識推理(GPQA)等測試中領先,數學正確率增超10%,長文本一致性提升。
- 快模型延遲降低,思考模型深度加強,但短提示下偶現保守回應。
突破七:40K tokens上下文+可控推理
- API三型號(gpt-5、mini、nano)支援400,000 tokens上下文(輸入272,000,輸出128,000)。
- 開發者可調reasoning_effort(含minimal模式)與verbosity控制推理與輸出詳度,支援JSON與語法約束工具呼叫。
圖片來源:資料圖片




