
日本 AI 國家隊爆醜聞!Rakuten 3.0被揭「偷用」中國DeepSeek 引大量開發者口誅筆伐

幾小時便被戳破的「幻象」
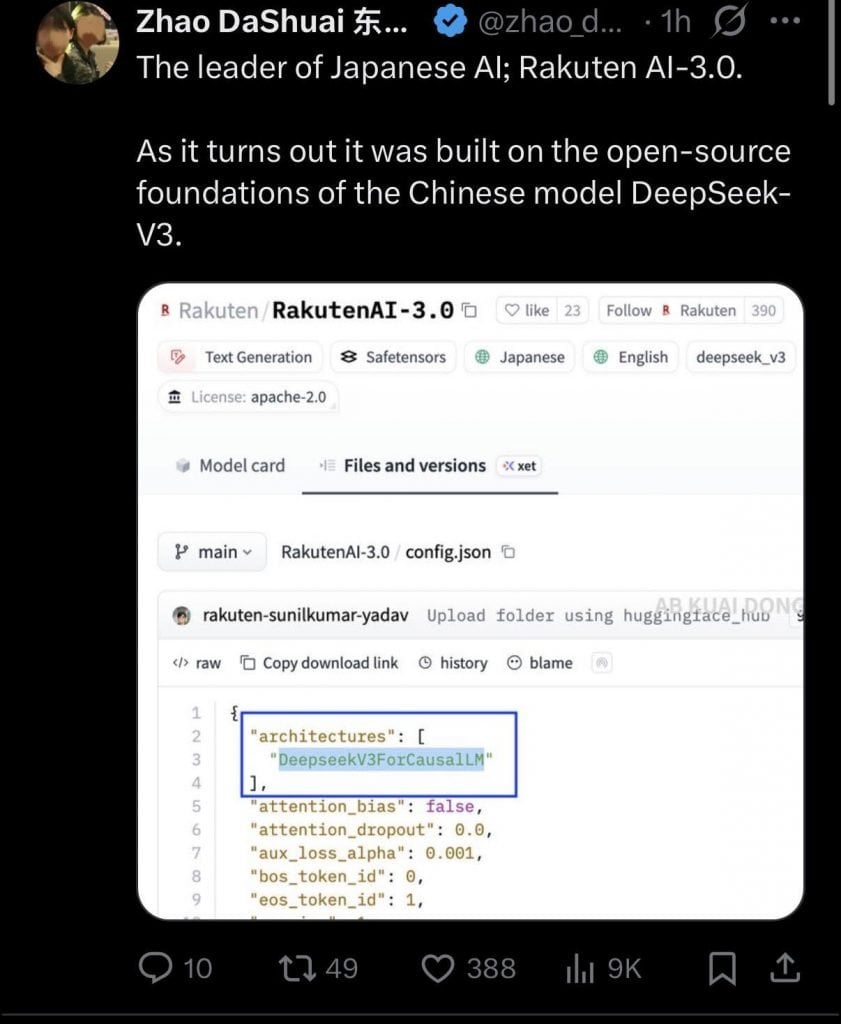
這套號稱擁有近「七千億參數」的混合專家架構模型,原被視為日本經濟產業省「GENIAC」國家計畫的重點政績。樂天在發布會上大肆宣揚,它能為整個生態系削減九成運算成本。可惜,在模型登陸 Hugging Face 平台後瞬間被拉下面紗:多位技術人員隨手一翻該模型的核心設定檔,發現了無可辯駁的證據:模型類型明確標示為「deepseek_v3」,架構宣告為 「DeepseekV3ForCausalLM」。。這顆剛推出的日本全新 AI,其出廠設定完全來自中國公司深度求索(DeepSeek)幾個月前公開的開源模型。
一模一樣的骨幹倒模
網絡社群裡的技術鑑證專家隨即進行了更深度的解剖。結果證實,無論是 61 層的神經網絡層數、256 個專家網絡數量,還是 7,168 維的隱藏層維度,樂天這套系統與 DeepSeek-V3 的骨架如出一轍。樂天工程師的實質操作,極可能只是拿了一批高品質的日文數據,在這個中國架構上進行了語言微調。將這種應用層面的加工包裝成底層架構的做法,本質上就是一場向政府和市場交差的把戲。
Rakuten AI 3.0 與 DeepSeek-V3 核心架構比對
| 參數項目 | Rakuten AI 3.0 數值 | DeepSeek-V3 數值 | 結果 |
|---|---|---|---|
| 神經網路總層數 | 61 層 | 61 層 | 完全吻合 |
| MoE 專家網路總數 | 256 個 | 256 個 | 完全吻合 |
| 隱藏層維度 | 7,168 維 | 7,168 維 | 完全吻合 |
| 模型總參數量 | 約 6810 億 | 6810 億 | 完全吻合 |
| 單次推論啟動參數 | 370 億 | 370 億 | 完全吻合 |
更改授權引來全球開發者的口誅筆伐
真正觸碰全球開源社群底線的,是這間跨國企業對版權協議的輕蔑。DeepSeek-V3 採用寬鬆的 MIT 授權,唯一條件是保留原始版權聲明。樂天最初上傳模型時,卻選擇將這份聲明徹底抹除,強行換上自家名義的 Apache 2.0 授權。這種在代碼世界被稱為「授權洗白」的操作,目的是令這個產品在審計文件上,看起來更像一個百分百自主研發的企業資產。直到被網民群起攻之,樂天才以擠牙膏的方式補回一份聲明文件。
延伸閱讀:甚麼是 MIT 授權?
這是目前世界上最簡單、也最常見的授權方式。它的核心精神就是:「隨便你怎麼用,但出事了別找我。」
特點:極度簡短,只有幾段文字。
任何人也可以:商業使用、修改原始碼、再授權、甚至把開源軟體包裝成付費軟體賣掉。
義務: 只有一條,用戶必須在軟體的副本中保留原始的版權聲明和許可聲明。
延伸閱讀:甚麼是 Apache 2.0 授權?
由 Apache 軟體基金會撰寫。它比 MIT 稍微複雜一點,但在法律層面上保護得更周全,特別是針對專利權的處理。
特點: 內容更嚴謹,明確定義了程式碼貢獻者的權利與義務。
關鍵差異(專利授權): 貢獻者在提供程式碼的同時,也自動授予用戶相關的「專利許可」。這意味著原作者不能事後反悔,控告用戶侵犯他的專利。
專利反擊條款: 如果用戶利用這個軟體去控告原作者侵權,那麼用戶對該軟體的授權會自動終止。
義務: 除了保留版權聲明,如果你修改了檔案,通常需要標註你修改過的地方。
防範對象反變國家大腦
這宗新聞在地緣政治層面上亦充滿了黑色幽默。日本當局瘋狂科水推動「GENIAC」計畫,最大誘因正是懼怕過度依賴中美兩國的技術會危害國家安全。就在 2025 年初,日本數位大臣才公開警告公務員慎用 DeepSeek,各大財閥也因為憂慮數據後門而內部封殺該模型。如今,這個由國家戰略資源孕育出來的國產希望,其核心正正就是官方千方百計防堵的中國演算法。
洗不掉的模型深層意識
技術架構可以抄襲,但深植於代碼中的意識形態卻無法洗底。大型基礎模型在訓練階段,無可避免會吸收開發者所在地的政治與價值觀。當日本網民以敏感的地緣政治問題測試 Rakuten AI 3.0 時,這個「日本國產」模型在釣魚島及台灣議題上的作答傾向,與北京的官方論述高度一致。這殘酷地證實了,表層的語言微調,根本無法撼動基礎模型在海量數據中建立的價值觀設定。
荒謬的技術食物鏈
樂天的翻車並非單一偶然,它精準描繪了當下 AI 產業那條荒謬的食物鏈。不久前,美國矽谷巨頭指控中國同業未經授權「蒸餾」其模型的推理能力,然後這個中國開源出來的模型,又再一次被急於向政府交功課的日本財團順手牽羊。這似乎引證了近年世界各地的 AI 企業,似乎全部都在計算著,如何用最低成本來獲取最大的政治與商業利益。
免責聲明:本專頁刊載的所有投資分析技巧,只可作參考用途。市場瞬息萬變,讀者在作出投資決定前理應審慎,並主動掌握市場最新狀況。若不幸招致任何損失,概與本刊及相關作者無關。而本集團旗下網站或社交平台的網誌內容及觀點,僅屬筆者個人意見,與新傳媒立場無關。本集團旗下網站對因上述人士張貼之資訊內容所帶來之損失或損害概不負責。



