
百度:文心一言在多項測試中 擊敗ChatGPT

廣告
人工智能領域的激烈競爭,中國網路巨頭百度(09888)表示,其為「中國版ChatGPT」的人工智慧(AI)聊天機械人「文心一言」(ERNIE Bot)的最新版本在多個關鍵指標上超越了廣受歡迎的ChatGPT。
百度3月推出了人工智能聊天機械人「文心一言」,該公司周二(27日)引用《中國科學報》報導表示,其最新版本文心一言3.5已超越ChatGPT的 GPT 3.5 模型綜合能力得分, 在中文能力部分也贏過GPT 4模型。
實測得分超ChatGPT
《中國科學報》引用的一項測試是基於標准入學和資格考試,例如進入大學或取得律師資格所需的考試。為驗證主流大模型的各項綜合能力,評測在AGIEval、C-Eval和MMLU三個權威評測基准上進行綜合評估。除了文心大模型3.5,評測的模型還有ChatGPT、GPT-4、ChatGLM、LLaMa系列大模型。
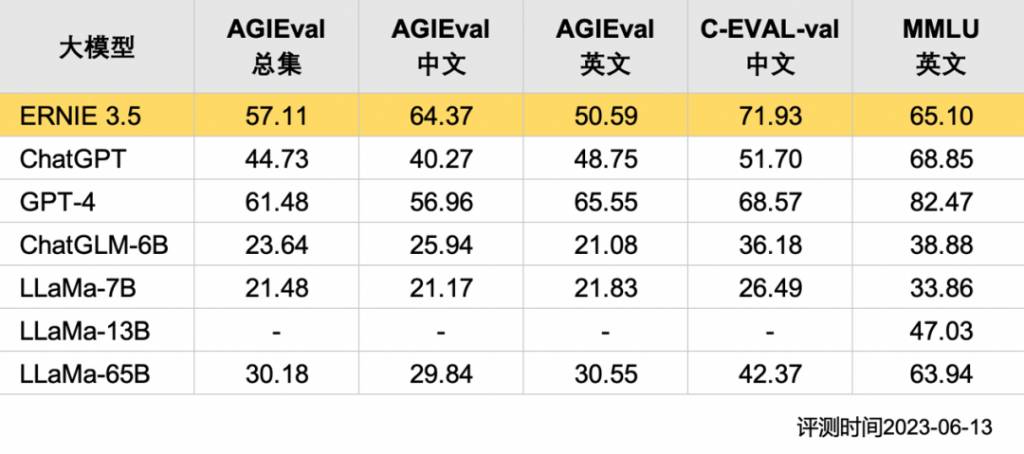
AGIEval評測基準包括普通大學入學考試(如中國的高考和美國的SAT考試)、司法考試、數學競賽、律師資格考試、國家公務員考試以及美國的GRE、GMAT等。而C-Eval則為中文基礎模型評測集,它包含13948個多項選擇題、涵蓋52個不同的學科,設置了四個難度級別,是面向中文語言模型的綜合考試評測集。MMLU是用於衡量模型的英文跨學科專業能力。該測試包含57個科目,涵蓋STEM、人文、社會科學等。
測試中,文心一言3.5超過GPT 3.5 在在AGIEval、C-Eval的分數。惟在英文MMLU測試中,GPT-4和ChatGPT的表現較好。
圖片來源:百度研究官網圖片、WeChat@中國科學報




